|
Mukund Varma T
I'm a I was fortunate to have spent several summers at Adobe, Nvidia, Apple, and Google with amazing mentors and colleagues. I have also had the opporunity to collaborate (and still continue to) with folks from the VITA Group at UT Austin. During my undergrad, I was also associated with the Advanced Geometric Computing Lab, and the Computational Imaging Lab. I am lucky to be supported by the Jacobs School of Engineering Fellowship. |

|
Research(superscript * indicates equal contribution)My current research interests lie at the intersection of computer vision, computer graphics and machine learning, specifically to facilitate high quality 3D reconstructions and semantic understanding from multiple view points. Some papers are highlighted. |
|
A Generalizable Light Transport 3D Embedding for Global Illumination
Bing Xu, Mukund Varma T, Cheng Wang, Tzumao Li, Lifan Wu, Bart Wronski, Ravi Ramamoorthi, Marco Salvi project / pdf / code / bib A framework to learn a generalizable 3D light transport embedding that approximates global illumination from 3D scene configurations. |
|
PhotonSplat: 3D Scene Reconstruction and Colorization from SPAD Sensors
Sai Sri Teja Kuppa*, Sreevidya Chintalapathi*, Vinayak Gupta*, Mukund Varma T, Haejoon Lee, Aswin C. Sankaranarayanan, Kaushik Mitra ICCP 2025 project / pdf / code / bib 
A framework to reconstruct 3D scenes from SPAD binary images, supporting colorization using a single reference blurry image or generative priors. |
|
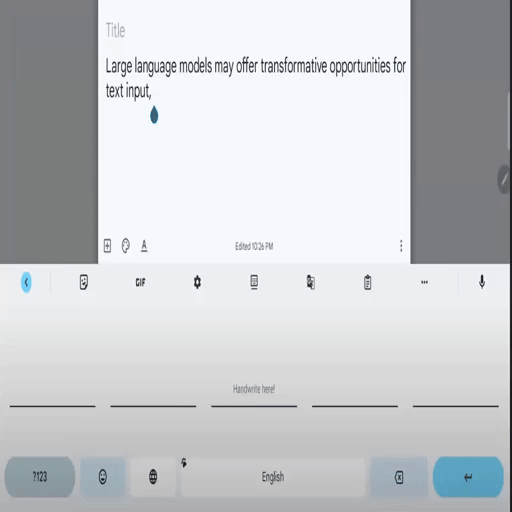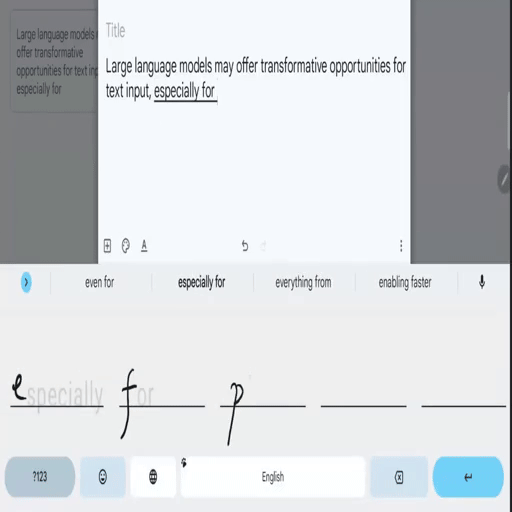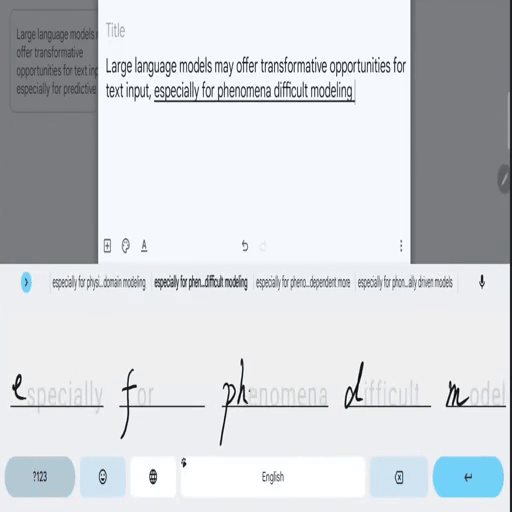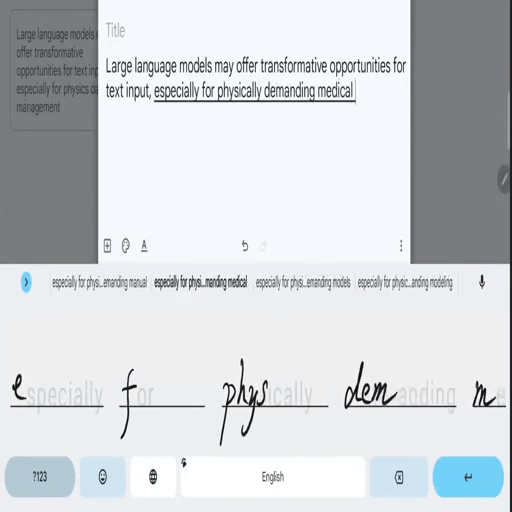
SkipWriter: LLM-Powered Abbreviated Writing on Tablets
Zheer Xu, Shanqing Cai, Mukund Varma T, Subhashini Venugopalan, Shumin Zhai UIST 2024. pdf / bib A framework that converts handwritten strokes of a variable-length prefix-based abbreviation (e.g. "ho a y" as handwritten strokes) into the intended full phrase (e.g., "how are you" in the digital format) based on the preceding context. |
 
|
GAURA: Generalizable Approach for Unified Restoration and Rendering of Arbitrary Views
Vinayak Gupta*, Girish Rongali*, Mukund Varma T*, Kaushik Mitra ECCV 2024. project / pdf / code / bib 
A generalizable framework for novel view synthesis using degraded input captures containing any imperfection type. |
 
|
A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
Kaiwen Jiang, Yang Fu, Mukund Varma T, Yash Belhe, Xiaolong Wang, Hao Su, Ravi Ramamoorthi SIGGRAPH 2024. project / pdf / code / bib 
A camera-free novel view synthesis technique from sparse input views (as few as 3 images of large-scale scenes). |
 
|
Lift3D: Zero Shot Lifting of Any 2D Vision Model to 3D
Mukund Varma T, Peihao Wang, Zhiwen Fan, Zhangyang Wang, Hao Su, Ravi Ramamoorthi CVPR 2024. project / pdf / code / bib 
General framework to lift any pretrained 2D vision model to generate 3D consistent outputs with no additional optimization. |
 
|
One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
Minghua Liu*, Chao Xu*, Haian Jin*, Linghao Chen*, Mukund Varma T, Zexiang Xu, Hao Su NeurIPS 2023. project / pdf / code / demo / bib 
Improves consistency of off-the-shelf multi-view generation techniques using a generalizable SDF, enabling super fast 3D generation from a single image. |
 
|
U2NeRF: Unifying Unsupervised Underwater Image Restoration and Neural Radiance Fields
Manoj S*, Mukund Varma T*, Vinayak Gupta*, Kaushik Mitra ICLR Tiny Papers 2024. pdf / code / bib A unsupervised learning pipeline for generalizable novel view synthesis and restoration of underwater scenes by disentangling into individual image formation components. |
 
|
Enhancing NeRF akin to Enhancing LLMs: Generalizable NeRF Transformer with Mixture-of-View-Experts
Wenyan Cong*, Hanxue Liang*, Peihao Wang, Zhiwen Fan, Tianlong Chen, Mukund Varma T, Yi Wang, Zhangyang Wang ICCV 2023. pdf / code / bib 
We scale up generalizable NeRF training by borrowing the concept of mixture of experts from language models. |
|
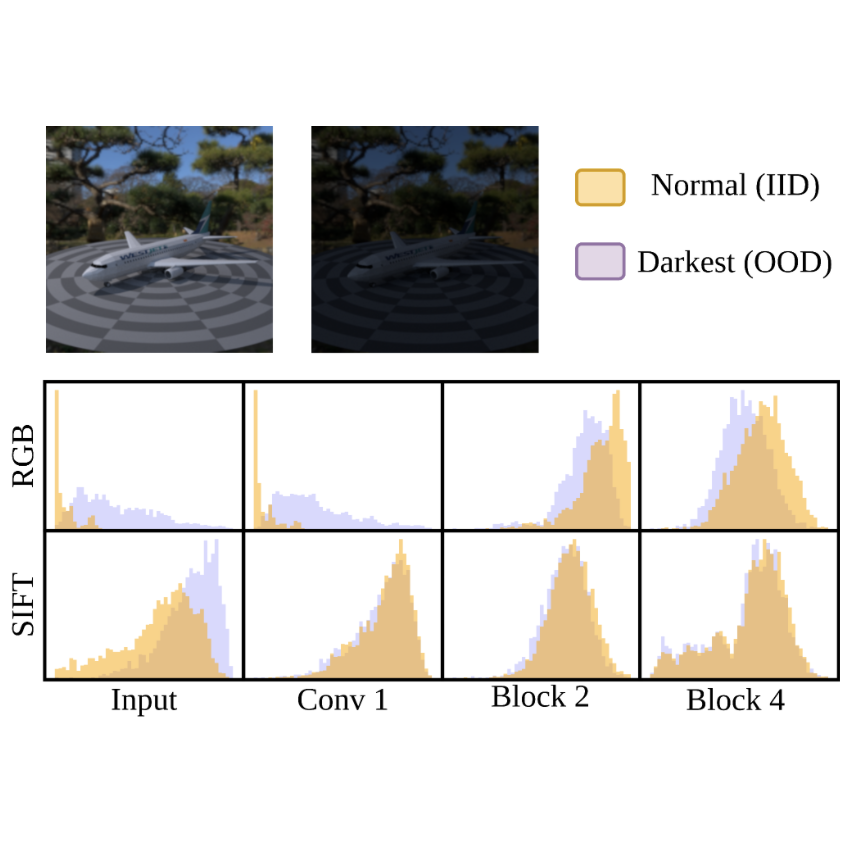
DeepSIFT: Rethinking Domain Generalization using Invariant Representations
Amil V Dravid, K Vikas Mahendar, Yunhao Ge, Harkirat Behl, Mukund Varma T, Yogesh S Rawat, Aggelos Katsaggelos, Neel Joshi, Vibhav Vineet under review. We present emperical evidence that convolutional networks trained on sift features improve robustness to unseen out-of-domain data with minimal to no-loss in in-domain performance. |
 
|
Is Attention All That NeRF Needs?
Mukund Varma T*, Peihao Wang*, Xuxi Chen, Tianlong Chen, Subhashini Venugopalan, Zhangyang Wang ICLR 2023. project / pdf / code / bib 
We propose a generalizable neural scene representation and rendering pipeline that achieves superior quality compared to previous methods. |
|
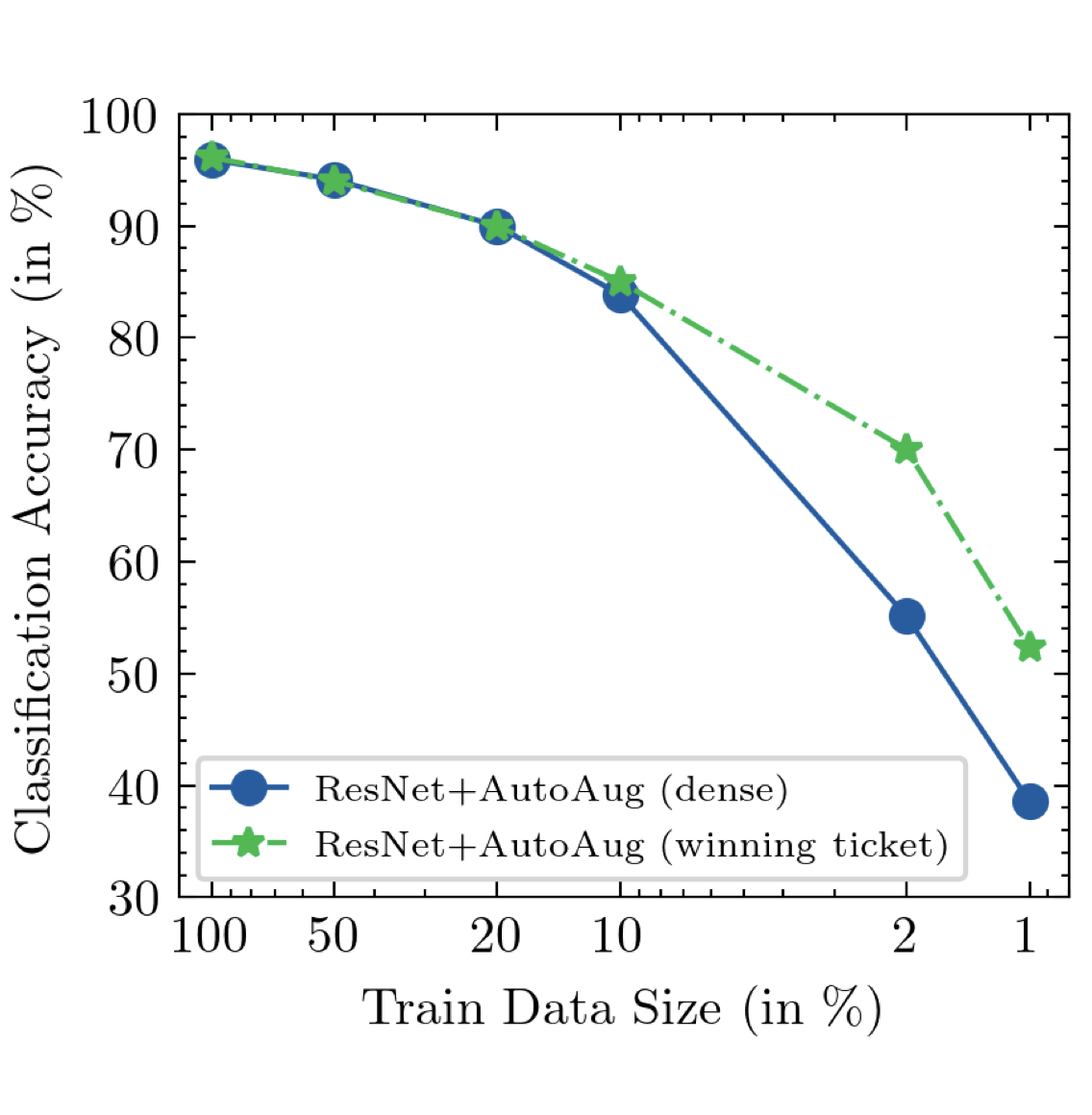
Sparse Lottery Tickets are Data Efficient Image Recognizers
Mukund Varma T, Xuxi Chen, Zhenyu Zhang, Tianlong Chen, Subhashini Venugopalan, Zhangyang Wang NeurIPS 2022 (Spotlight). pdf / code / bib 
Sparse networks identified using iterative magnitude pruning showcase improved data-efficiency and robustness compared to their dense counterparts. |
|
NL Augmenter: A Collaborative Effort to Transform and Filter Text Datasets
Kaustubh Dhole, Varun Gangal, ... Mukund Varma T, Tanay Dixit, et al. NEJLT 2023 (GEM Workshop, IJCNLP 2021). pdf / code / bib 
Collaborative repository of natural language transformations. |

|
BIG Bench: Beyond the Imitation Game Benchmark
Jascha Sohl-Dickstein, Guy Gur-Ari, ... Mukund Varma T, Diganta Misra, et al. TMLR 2023 (WELM Workshop, ICLR 2021). pdf / code / bib 
Collaborative benchmark for measuring and extrapolating the capabilities of language models. |
 
|
ShapeFormer: A Transformer for Point Cloud Completion
Kushan Raj*, Mukund Varma T*, Dimple A Shajahan, Ramanathan Muthuganapathy under review. A specialized pipeline for point cloud shape completion that can generalize to synthetic and real partial scans from seen and unseen categorical types. |
 
|
[Re] On the Relationship between Self-Attention and Convolutional Layers
Mukund Varma T*, Nishanth Prabhu* ReScience-C (MLRC, NeurIPS 2020). pdf / code / bib 
We introduce Hierarchical Attention, a reccurent transformer module that immitates convolution-like operation with significantly lower computational budget. |
|
|
Point Transformer for Shape Classification and Retrieval of Urban Roof Point Clouds
Dimple A Shajahan*, Mukund Varma T*, Ramanathan Muthuganapathy IEEE-GRSL 2021. pdf / code / bib We propose a transformer architecture for sparse set learning, e.g. point cloud understanding. |
Academic Service
|
MiscI enjoy hiking ⛰️ (cuz duh I am a boring computer science kid), used to sketch ✏️ a bit, and love playing most sports, particularly badminton 🏸, tennis 🎾 and soccer ⚽. |
{kind=link}
|
Template stolen from here. |